MDP(Markov Decision Process) 란?
앞서 보았던 MP의 심화형으로 Markov Reward Process 에 Decision을 추가한 것으로
MP가 이전 상태에만 영향을 받았다면
MDP는 이전 상태와 취한 행동에 영항을 받고 그에 대한 보상이 있는 것이다.
State
Agent가 인식하는 자신의 상태. 사람의 경우 오감으로 인식하는 모든 상태가 될수 있고,
Atari게임에서는 게임화면 그자체의 pixel값이 된다.
즉, 어떠한 문제에 대한 상태는 정의 하기 나름이다.
같은 문제라도 다른 ML 알고리즘을 적용하면 더 나은 결과를 가져오는 문제가 있을수 있으므로 잘 비교해보고 선택해야한다.
강화학습은 이전에도 설명했지만 '시간'의 개념이 적용된 문제를 푸는데 사용하는 ML기법이므로 강화학습의 목표가 Policy가 됨을 의미한다.
Action
Agent의 역할은 환경에서 어떤 특정 상태에 도달했을때 해야할 행동을 지시하는것.
Robot으로 보면 어떤 위치에서 오른쪽으로 간다, 왼쪽으로 간다. 등의 명령이 action이 되는 것이다.
State transition probability matrix
Agent가 Environment 상에서 action을 통해 state가 바뀔수 있는 경우의 확률을 행렬로 표현한 것.
action을 취할때 state가 결정되어있는것이 아닌 확률적으로 정해지는것은 일종의 noise라고 생각하면 된다.
Markov Chain
역으로 MDP에서 action과 reward가 없는 것을 생각해보자.
state와 state간의 transition matrix를 생각해 볼수 있다.
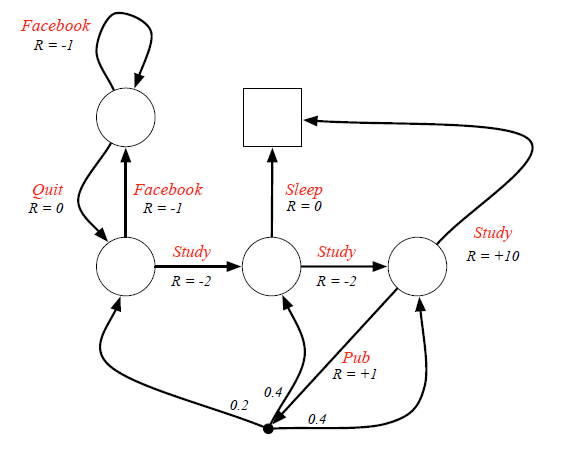
아래 그림은 학생의 하루를 MC의 그래프로 나타낸 것이다.

학생의 state를 표현하고 그 state간의 transition 확률을 나타낸 것이다.
여기에서 transition 확률을 action을 할 확률 + action후 어떤 state로 갈지에 대한 확률로 바꾸게 되면 MDP가 된다.
Reward
Agent가 어떠한 action을 취하면 그에 따른 Reward를 Environment가 Agent에게 알려준다.
Reward는 문제에 따라 다르게 설정된다.
정의는 State s일때 Action a를 취했을때 얻는 reward 이다.

이 reward를 immediate reward 라고 하는데 agent는 이 reward 뿐 아니라 이후로 episode 동안 얻는 모든 reward를 고려한다.
Discount Factor
Reward를 단순히 더해나가기만 하면 크게 2가지 문제가 생긴다.
1. 어떤 agent는 각 time step마다 0.1씩 reward를 받고 다른 agent는 1씩 받았을때 시간이 무한대로 흐르면 결국 두 agent 모두 reward는 무한대로 간다. 무한대끼리의 비교는 없다.
2. agent가 episode 시작과 동시에 reward를 1 받고 끝난 경우와 끝나기 직전에 1을 받았을 경우의 구분이 불가능하다.
이 문제들을 해결하기 위해 나온 개념.
조삼모사를 고려하는 개념.
보통 0~1사이의 값을 사용하고 0에 가까우면 근시안적. 1에 가까우면 미래지향적으로 판단함.
Agent-Environment Interface
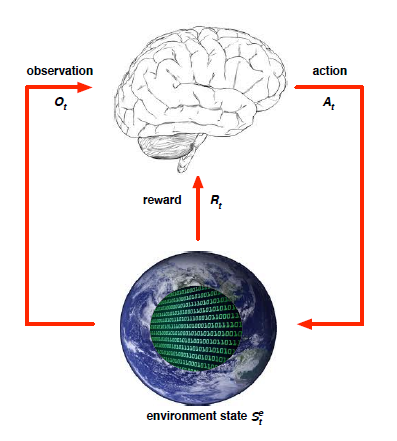
위와 같이 Agent는 Environment와 상호작용하며 action을 취해 state를 변경하며 학습한다.
observation을 통해 현재의 state를 파악하고 state에 맞는 action을 취하면 environment의 reward를 agent가 받는다.
초기에는 random action을 취한다.
Policy
agent가 어떠한 state에서 어떤 action을 취할지 정하는 방법을 말한다.
강화학습의 목적이 Optimal policy를 찾는 것이다.
정의는 State s에서 Action a를 취할 확률을 이야기 한다.

이 모든걸 정리하여 MDP를 그래프로 표현하면 다음과 같다.
'{Programing} > {AI}' 카테고리의 다른 글
| Fundamental of Reinforcement Learning 공부 정리!!(5) (0) | 2017.11.05 |
|---|---|
| Fundamental of Reinforcement Learning 공부 정리!!(4) (0) | 2017.10.14 |
| Fundamental of Reinforcement Learning 공부 정리!!(2) (0) | 2017.09.25 |
| Fundamental of Reinforcement Learning 공부 정리!!(1) (0) | 2017.09.25 |
| 딥러닝 실습 1. Python 기본 문법 (0) | 2017.03.02 |
